
Markov Decision Processes Introduction
Contents
Markov Decision Processes Introduction#
Markov Decision Processes is the most fundamental concept that you will learn in this course because everything in the future sections of this course is based on this concept. Q-Learning, Deep Q-Learning etc., are all derived from this framework.
To have a continued context of what we are doing, we shall use the example of the Grid World Environment. The reason for choosing this environment is that all the states and transition proababilties can be made visible in an intuitive way.
We start with learning about the Markov property and the Markov Models. Markov models have a wide range of applications, including:
Google’s PageRank algorithm was derived based on Markov model.
Hidden Markov models are an important algorithm for speech recognition and genomics.
Markov Chain Monte Carlo has become widely popular for its application in Bayesian Machine Learning.
Finance (Random Walk Hypothesis).
Control Systems.
Once we discussion MDP, we shall build upon these concepts and introduce definitions for Reward, Value functions, Bellman Equation, and so on.
Once these definitions are introduced, we shall discuss algorithms to solve the Bellman equation.
Environment and Notations#
Let’s understand the environment that we will be working with throughout this section. We shall also define some essential notation for RL in this page.
Gridworld#
Gridworld is the simplst environment that is you can use in RL to enables to think about and understand all the concepts. Gridworld is the perfect sized environment without being too complex or too simple.
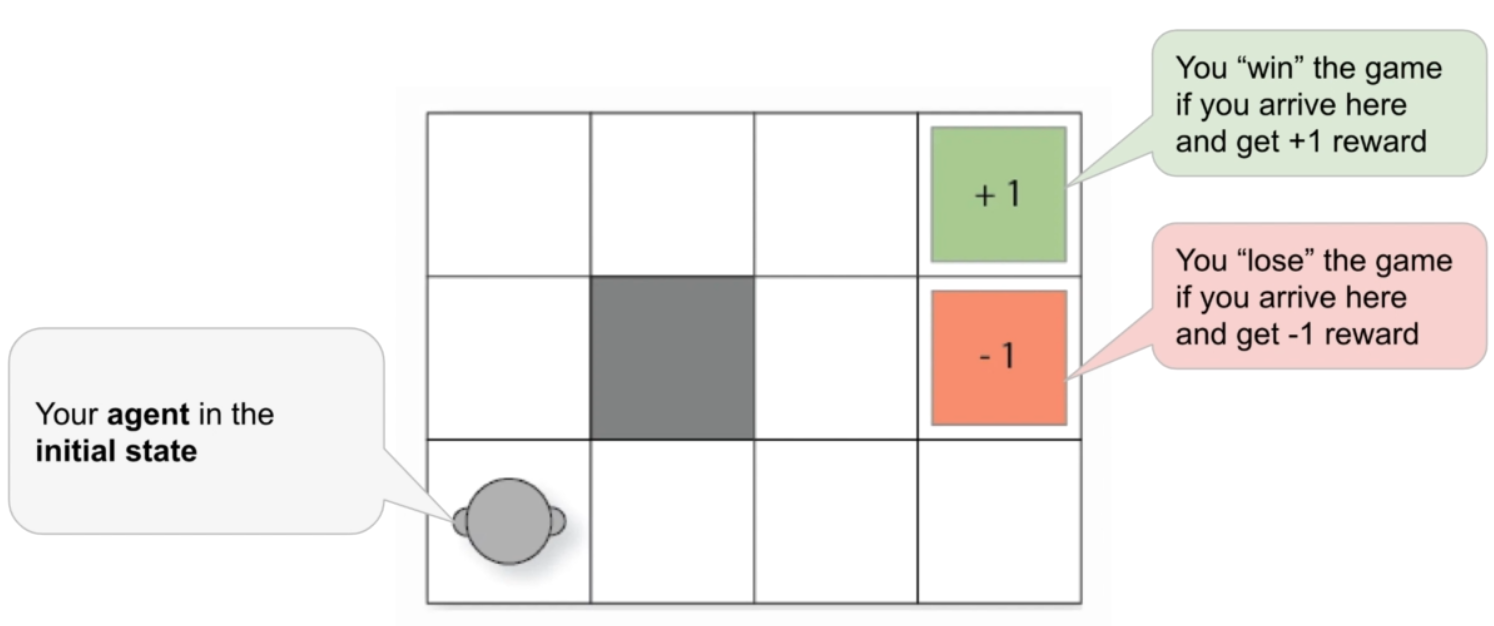
Fig. 63 Gridworld Environment#
For the purpose of this page, Gridworld is considered at a \(3 \times 4\) table that your agent(bot) lives on. The agent can move up, down, left, or right one square at a time. The goal (to be defined) of the agent is to reach the top right corner which is considered to be the winning state (to be defined) to receive the reward (to be defined). Just underneath the winning state is the losing state with a negative reward. The goal of the agent is not only to reach the winning state, but also to avoid the losing state.
In RL, the agent does not have any concept of winning or losing, it only receives a reward (either positive or negative). The only objective of the agent is to maximize the overall reward. The agent simply behaves like “I want to go the top right box as it gives me the maximum reward.”
Having established the Gridworld environment, lets define the building blocks of the environment.
Gridworld States#
A state can simply be defined as the position of the state. The position (2,0) simply defines the initial state of the agent. The winning state is denoted by (0,3). Note that there is a wall at (1,1) which represents a state that the agent cannot occupy. See the image below for reference.
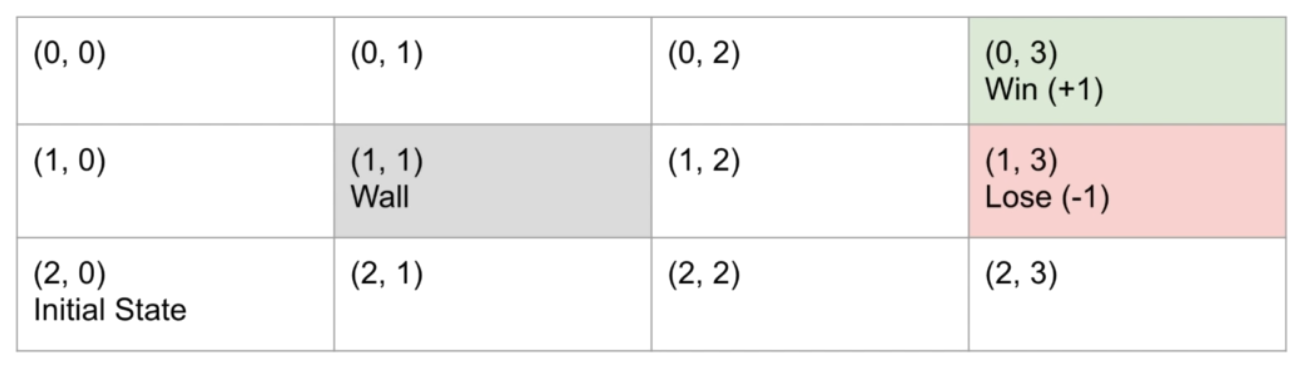
Fig. 64 Gridworld States#
Set of all possible states is known as the State Space. For the Gridworld environment, the state space is {‘up’, ‘down’, ‘left’, ‘right’}.
More Terminology#
The point of Reinforcement Learning is that we want to reinforce the desired behavior of the agent. This implies that the agent does not play our gridworld game just once, it plays the again multiple times and learn from the feedback it received each time. We hope that by the end, the agent will learn to play the game and receive the maximum reward. These concepts seem pretty intuitive because thats how the human learning experience works. However, do not take these simple concepts for granted because modelling this learning behaviour in computers takes a lot of effort. Instead of calling the gridworld a game, we can each play of the agent an episode. The agent learns from each episode to find an optimal way to maximize the reward.
Let’s define the meanings of winning and losing states. Just because the agent lands in a state and receives +1 or -1 reward, does not mean that the episode is over. Each state can give you any reward and is not an indication whether a state is terminal or not. A Terminal state is a state that ends an episode. (Can be thought of a life in super mario). So far we have defined episodes, state spaces and terminal states.
Episodic v/s Non-episodic tasks#
Gridworld and Super-mario are examples of episodic tasks. On the other hand, we can have non-episodic tasks, also called continuous tasks. One example is controlling the temperature in a room. For most RL algorithms it is assumed that the task at hand is episodic.
More about environment#
The envioronment describes the “world” that the agent lives in. Examples: Pong, Super-mario, Gridworld, Chess. When we say an environment is solved, we mean that we have built an agent that receices reward that surpasses a threshold that we have set.
Policy#
The policy can be thought as the “Brain” of the agent. The policy is a “function” that maps a state to an action. The important point to note is that a policy (almost) always leads to a winning state. In the below figure we see 2 policies that lead to the winning state.
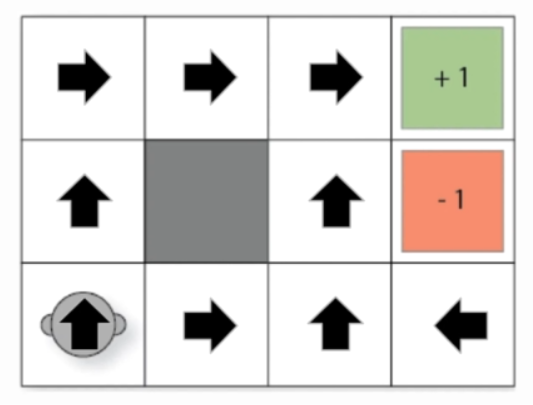
Fig. 65 Policy#
Deterministic Policy vs Stochastic Policy#
One confusion while defining a policy might be where it should be deterministic or stochastic. Is it a function in computer program? An equation? A Neural Network?
For Stochastic policy \(\pi\) is a probability distribution of all possible actions given a state \(s\). For example a stochastic policy would be to use epsilon-greedy to select an action given a state. Action space is the set of all actions, analogous to state space.
Rewards#
Rewards are engineered in such a way that these rewards result in the behaviour that we want the agent to have. One example of this is trying to make an agent to solve a maze. One potential issue with assigning reward to only the final state is that, the agent might just wander in all other states thinking that there is no actual reward present in the environment.
A solution to this issue is to assign a negative reward for every time-step or random negative rewards so that the agent tries to learn the environment.