
The Markov Property
Contents
The Markov Property#
“All models are wrong, but some are useful.” - Box, George E.P.; Norman R. Draper (1987)
The Markov property seems unrealistic, and despite that it underpins multiple sub-fields of Machine Learning.
Let’s understand the markov property from the context of Language models. Consider: Sentences are sequence of words, and words are states. Example Sentence: “A quick brown fox jumps over a lazy dog.”
Suppose you are given the entire sentence except for the last word and you are asked to predict the last word. This can be formulated as a probability distribution. What is the word at time 9 given all the words until time 8.
One might think that training such a language model might require us to consider all possible sentences in the english language. This is almost impossible.
Markov property states asks us to only consider the previous word to predict the next word. More formally,
The first-order Markov Property states that:
This means the state at time \(t\) only depends on the state \(t-1\). Second-order markov property is where the state at \(t\) depends on both states at \(t-1\) and \(t-2\). This property is somewhat restrictive. What if the word at time \(t\) is the. This makes it almost impossible to predict the next word accurately. In reality, the markov property works surprisingly well. Why does Markov Property even work? see more In environments such as Atari games, a state is usually considered as a group of 4 (or n) frames. This means that an observation is not equal to the state and hence we have both observation space and state space.
The State Transition Matrix#
One of the key ingredient of the Markov Property is the State Transition matrix. In order to express the probability of going from one state to another, we need two inputs, the current state and the next state.
Using maximum likelihood we can count the event of \(i \rightarrow j\) from state \(i\).
Diving deep into Markov Decision Processes#
We now have all the ingredients to dive into MDPs. In a single sentence, we can define MDP as a discrete-time stochatic control process.
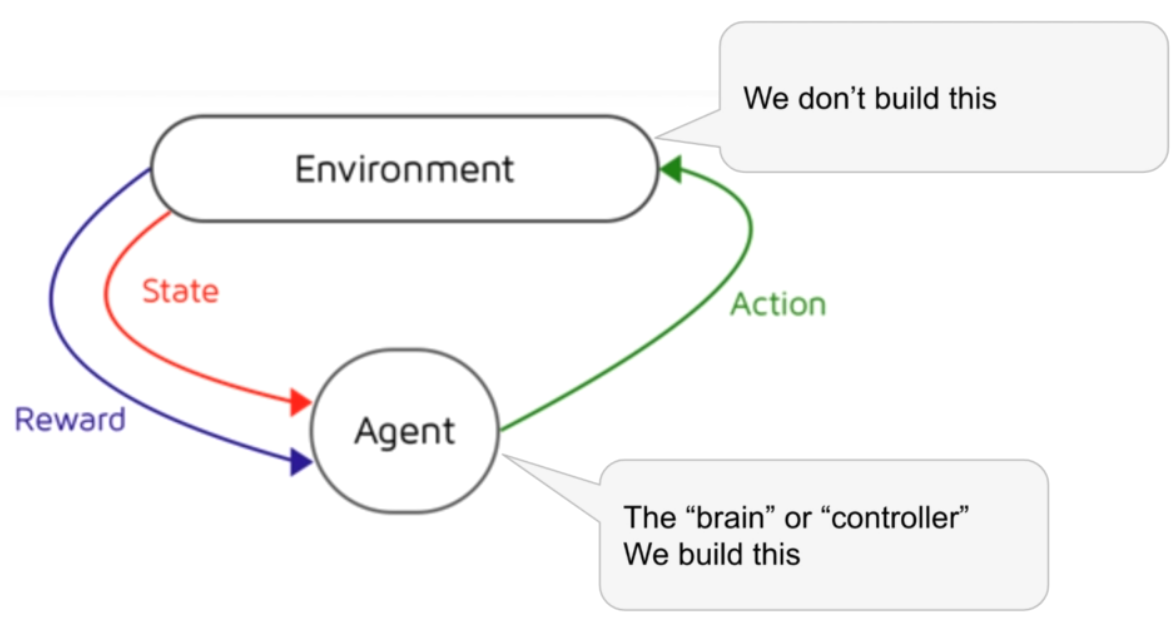
Fig. 66 Markov Decision Process ingredients.#
Environments are defined (not really built). We try to build the learning agent that navigates (interacts) with the defined environment and solve the same.
From the above figure it can be inferred that the agent takes an action in the environment (that may or may not change the environment). The environment then returns a feedback to the agent. This is in the form of reward and the next state.
Importance of noticing the time indicing during the action-reward loop#
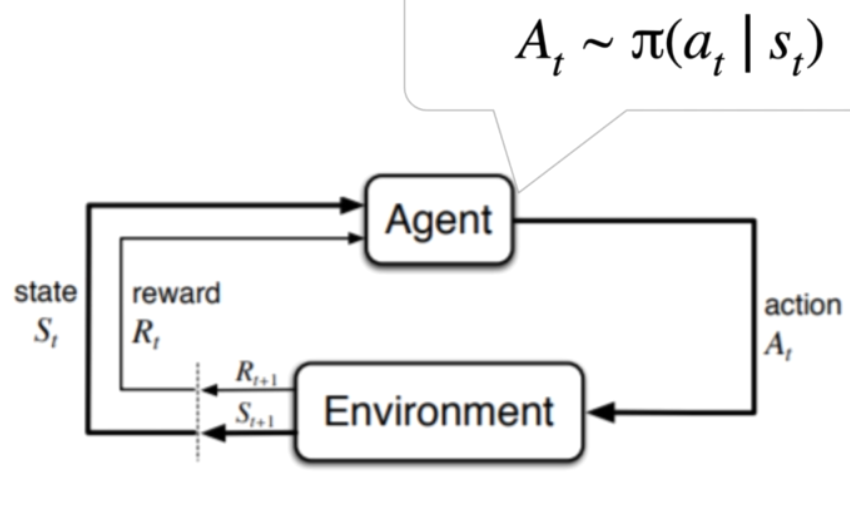
Fig. 67 Markov Decision Process ingredients.#
Suppose the agent sees the environment at the current time \(t\). The action chooses an action \(A_t\) from the policy \(\pi (a_t | s_t)\) (notice both action and state have the same time index \(t\)). The Action \(A_t\) is input to the environment and this brings us to the next time-step. The increment in time-step is implicit in the environment. The agent now arrives in the next state \(s_{t+1}\) and receives the reward of \(R_{t+1}\). All together this forms the tuple for a single step in an MDP. Transition step = {\(S_t, A_t, R_{t+1}, S_{t+1}\)}
Another ways to represent the above tuple can be \({S_t, A_t, R_{t+1}, S_{t+1}, A_{t+1}}\) or dropping the time indices entirely as \({ s, a, r, s'}\). Notice that reward \(r\) occurs at \(t+1\) but is not represented as \(r'\).
The transition probability of the next state given a previous can be used to represent both Deterministic and Stochastic environments. Similarly the policy \(\pi(a_t | s_t)\) can be used to represent both deterministic or stochastic policies.
Deterministic and Stochastic Rewards#
One might think how can rewards be stochastic. In games such as gridworld, given a deterministic environment, the rewards for the states can be defined as deterministic (meaning each state has its own reward attributed and does not change).
However, in games such as chess or tic-tac-toe, reaching a specific state does not mean that the same exact reward will be received every single time. The reward for some states can be higher and might be changed based on the current scenarion. Having said that, these rewards can still be converted to deterministic by defining the return as either a win or lose based on the outcome of the episode. However, this leads to yet another problem where agent just wanders around without a proper idea or understanding of where to expect the rewards. Thus it makes complete sense to define rewards as both deterministic and stochastic based on the environment or the problem to be solved at hand.
Now let’s break down the phrase “Discrete-time stochastic control process”.
Stochastic process == Random process.
Discrete-time == Each step the agent plays is discrete. (Computers themselves are discrete time). (However, continuous actions are seemingly continuous).
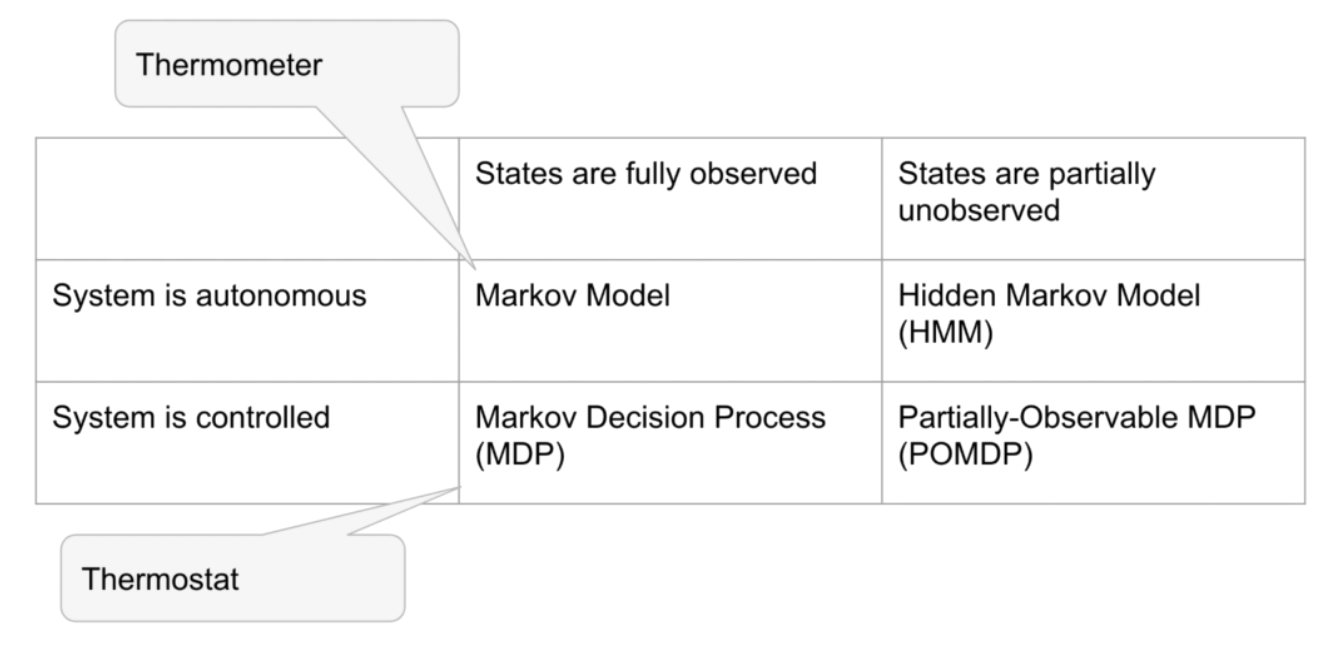
Fig. 68 Controllable and autonomous systems.#