
Future Rewards and Value functions
Contents
Future Rewards and Value functions#
In this page, let’s get more specific about what the agent does. We have previously talked about how our agent wants to maximize the reward. However, this is not specific enough.
Given an episode of time \(T\), our true goal is to maximize the sum of total rewards over all the time-steps in the episode.
An important consideration in MDPs is that our actions only effect the future rewards, hence our aim become to maximize the sum of all future rewards from a given time-step. If we are in the initial stage of the episode we want to maximize the sum of all the rewards over that episode.
We use the letter \(G\) to represent the sum of future rewards.
If the reward function \(R(t)\) is stochastic (random variable), then the reward function \(G\) is also stochastic (random variable).
At any given time the goal of the agent is to maximize the return \(G(t)\) that occur at all the future steps from \(t\).
Planning#
In RL, the reward that we are looking for happens at the very end of the game or sometime in the far future. Examples are solving a maze or winning a game. You want the agent to plan the strategies to reach the goal. This strategy finding element is automatic.
Discounting rewards#
One important addition to the reward functions is down-weighting rewards that are further into the future.
\(\gamma\) - discount factor
Another intuitive way to think about discounting is that “the further you look into the future, the harder it becomes to predict the true reward.” Discounting allows us to say that “The near future is more important.”
If \(\gamma = 0\), the reward only depends on the next time-step. This can be called as a greedy strategy. We only care about the immediate reward.
If \(\gamma = 1\), the reward depends on all the future time-steps equally. This is the closest to what we would want a perfect agent to account for.
The real purpose of using discounting is to improve the training process. If you have an environment that has very short episodic-tasks , then it might not be worth using discounting at all.
Usually the values of the discounting factor \(\gamma\) are around \(\{0.9, 0.99, 0.999\}\) and so on. \(\gamma\) is a hyperparameter and requires tuning. (use gridsearch).
Value Functions#
Let’s reinitialize the fact that the goal of our agent is to maximize the sum of future rewards. How does the agent know what the sum of future rewards will be?
Clearly this is dependent on the policy. Let’s take another look at the GridWorld.
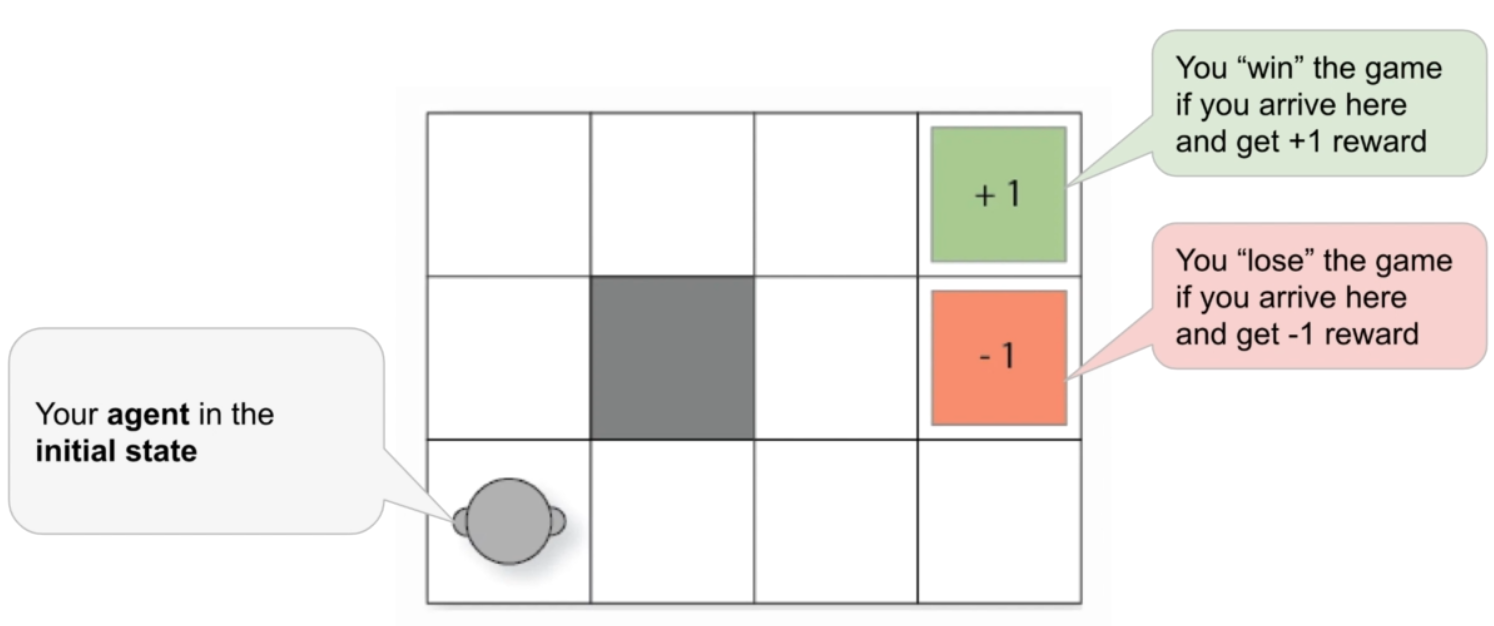
Fig. 69 Gridworld Environment#
If the agent take the two routes that lead to the goal position, no matter what step (action) the agent might take, the sum of the future rewards is always +1. (Assuming that the reward is defined as +1 if the agent reaches the goal position and -1 if the agent reaches the position below the goal position. (see figure above)).
On the other, if the agent follows a policy that always leads to the state that gives -1 reward, the sum of the future rewards will always be -1.
Let’s now consider another setting of the same environment, where we receive -1 reward in every state other than the goal state, and the policy leads to the goal position only.
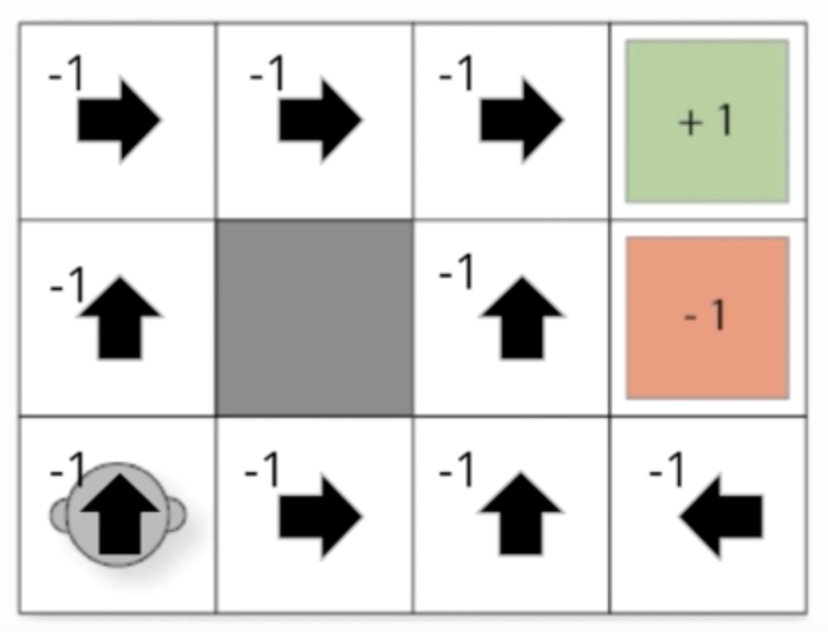
Fig. 70 Rewards for each state are -1 except goal state.#
The difference between this example and the previous example is that, now the return to the agent is dependent on the state of the agent.
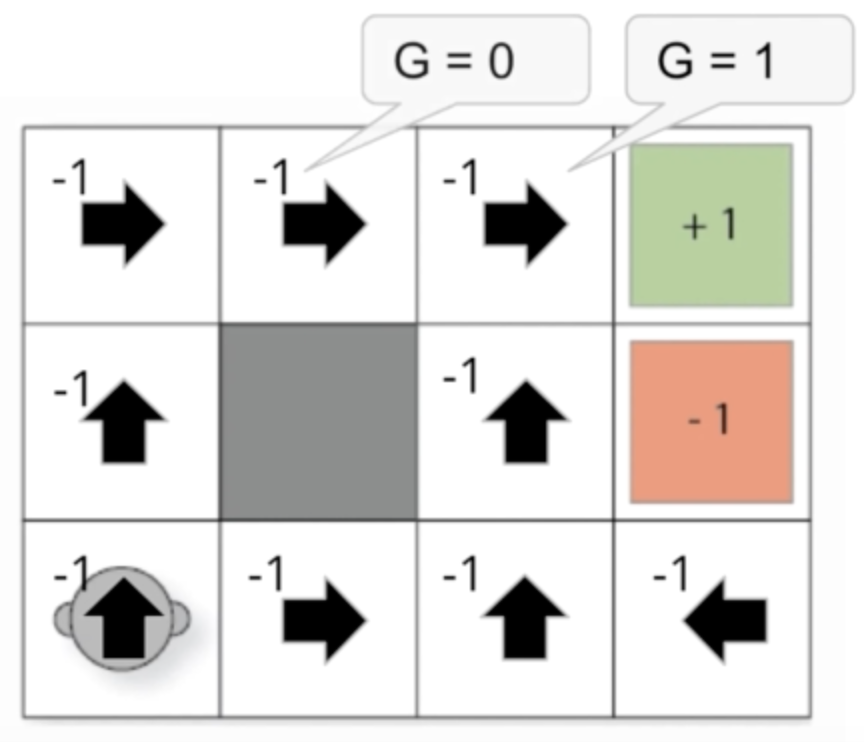
Fig. 71 Return is dependent on state.#
The general the return from any particular state is dependent on what state you are in. This is also true with discounting as well.
The main takeaway here is that the return is not only dependent on what pocily the agent is following, but also on what state the agent is in.
What if the return is random?#
The above example assumes returns to be deterministic. In case of stochastic environment, the transition function \(p(s', r| s,a)\) makes the return stochastic.
In this sceario, does it even make sense to maximize the reward even when the reward is not known (random)?
This is the reason why the return is defined as a random variable. What we really want to maximize is the expected return (or the expected value of the return) over time.
This is also called Value function. It is defined as the expected value of the return given a state \(s\) under the policy \(\pi\).
where \(G(t) = R(t+1)+ \gamma R(t+2)+ \gamma ^2 R(t+3) ... = \sum_{\tau = 0}^{\infty}\gamma^\tau R(t+\tau +1)\)
\(\gamma\) - discount factor
One point to remember is that the value of a terminal state is 0. Because in a terminal state there are no future rewards.