
Introduction and the Pinhole camera
Contents
Introduction and the Pinhole camera#
Have you ever wondered what complex mathematics runs behind the miniature camera that we use in our every day life. Point and shoot cameras are ubiquotous to a point that we take camera technology for granted.
Consider an image of a railway track.

The rails look as if they converge at the end, however, we know that they do not. The depth of the scene is lost in the image (as the picture is a 2D image). The imperative question arises How do we map a 3D object onto a 2D image? Better yet, How to map a 3D point in space on a 2D plane? While making this 3D to 2D mapping, what is the information about the scene that is lost? What illusions would arise?
This section aims at answering the above questions while providing a detailed explanation of the pinhole camera.
Computer Vision Overview
Low-level vision
Image processing
Edge detection
Feature detection
Cameras
Image formation
Geometry and algorithms
Projective Geometry
Stereo Vision
Structure from motion
Recognition
Face detection/recognition
Category recognition
Image segmentation
To model a camera, one must make sure to preserve both geometry and semantics of the scene. Some applications of computer vision include but not limited to Single View modelling, Detection and Recognition, Visual Question and Answering, Optical Character Recognition, Entertainment (e.g., Snapchat), Shape Reconstruction using depth sensors, Building rome in a day!, 3D Scanning, Medical Imaging and so on.
Image Formation#
How a colorful image is formed? All the images are a resultant of the following entities:
Lighting Conditions
Scene Geometry
Surface Properties
Camera Properties
The focus of this course is predominantly on the Camera Properties. The image formation requires a light source (e.g., sun) continuously emits photons. These photons are reflected by the surface and a portion of this light is directed towards the camera.
The sensor plane (the film) has physical existence, but the image plane is virtual. The image plane is flipped upside down as compared to the sensor plane.
Pinhole camera model#
The pinhole camera makes sure that every unique point in the physical space falls on the film.
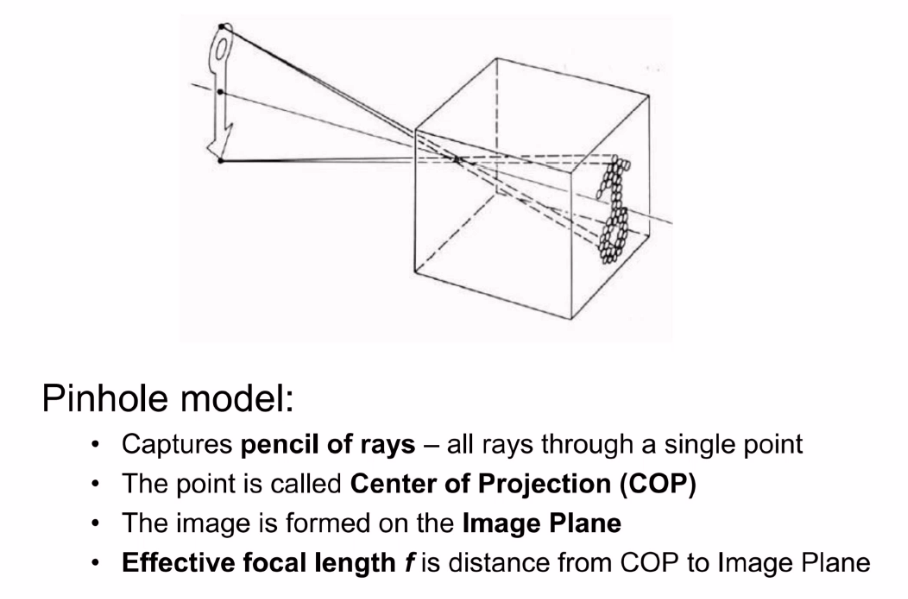
Fig. 1 Pinhole camera#
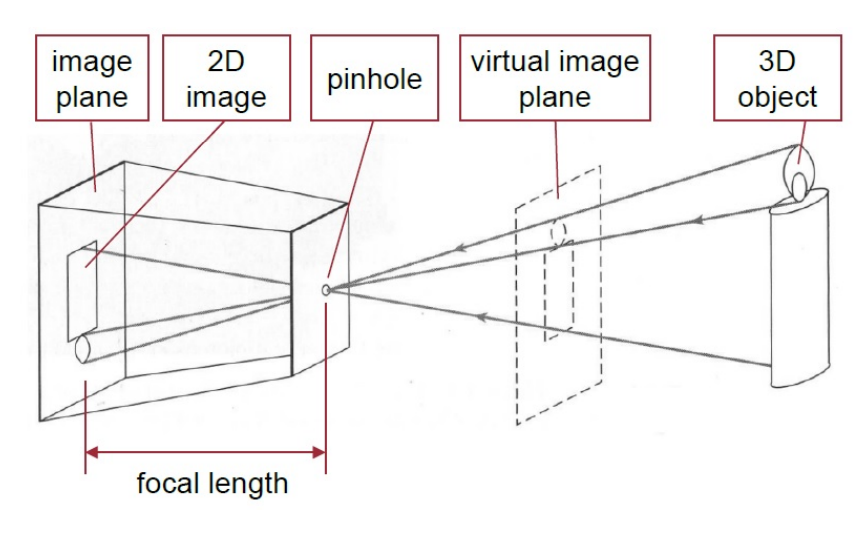
Fig. 2 Pinhole camera Model#
The image that we see on the screen after taking an image is virtual image plane. Same phenomenon happens in human eyes.
Zooming in and Zooming out changes the focal length of a camera. (Not digital zoom, optical zoom)
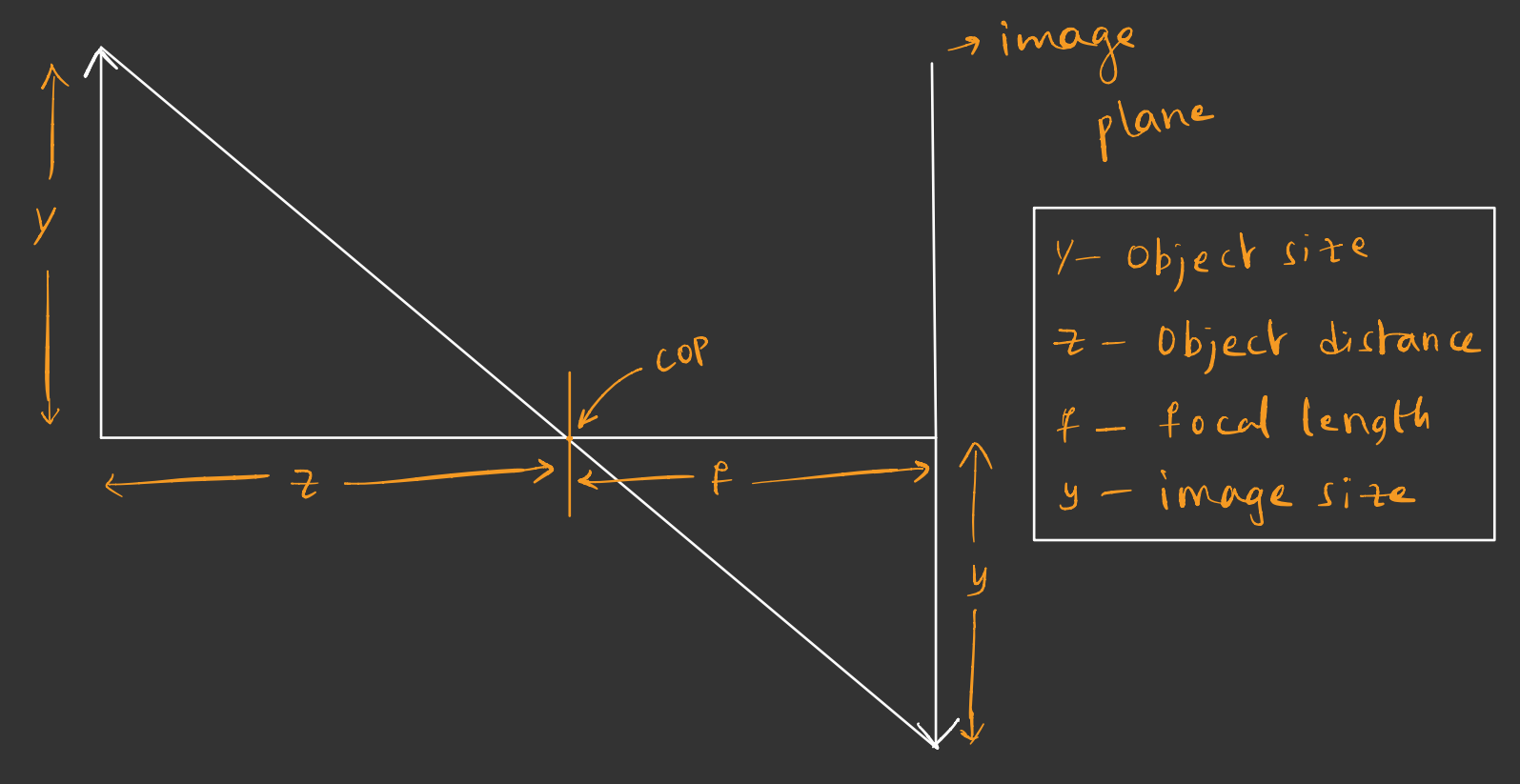
Fig. 3 Pinhole camera 2D representation#
The above diagram gives us the first equation for image formation in computer vision. Given a 3D point \(P =(X,Y,Z)^T\), the camera projects this point to onto a \(2D\) image plane to \(p = (x,y)^T\). From the above figure:
This is the simplest form of perspective projection. You can change the size of the image by changing any of the above 3 parameters. For a simple example of human face, the image size can be increased by i) actually having a bigger object size \(Y\), ii) increasing the focal length \(f\), and iii) bringing the object closer to the camera (decreasing \(Z\))
In the above figure the focal length is the only parameter that can be changed (as the size of the object and the distance from camera is assumed to be fixed.) This means that upon increasing the focal length the size of the image increases proportionally. When we zoom in, we increase the focal length.
If I zoom in/out of a picture after taking a picture, will focal length change?
After taking a picture, if you zoom in and zoom out, it is a digital zoom. It does not change the focal length of the camera.
How to calculate the default focal length of a smartphone camera?
The aim of a camera is to map each of the 3D point in the 3D world to a location in the 2D image plane. Camera does the 3D-2D mapping. It is also called as the Perspective projection. This leads to a question about how to recover a 3D location of a point from a 2D image.
While projecting from 3D to 2D, the depth information is lost (also the angles between objects in 3D) are lost. Each ray becomes a pixel on the image plane.
Note
In the above perspective projection, the angle between lines is not preserved and the depth information is lost.
When the distance between camera and the object is too large (god’s view), the difference in sizes of closer objects and far objects is not preserved.
\(x = sX, y = sY, \text{ where } s=\frac{f}{Z_0}\), \(Z_0\) is the distance between camera and the object.
Projection Matrix and the Intrinsic parameters#
The simplest form of perspective projection in matrix form is given by the above equation.
What is the need for extra row in the 3D coordinate?
The extra column of zeros and the extra 1 in the 3D coordinate is added to incorporate the translation.
What do the distances \(X, Y, Z\) mean here?
\(X,Y,Z\) are the relative coordinates of a 3D point from the camera origin. This means that when the object is moved or the camera is moved, the values of \(X,Y,Z\) change.
This leads us to the question, What about the values of \(x,y\)? These pixel values are relative to the origin Principal point of the image plane. Typically the origin of an image is located at the bottom left or the top left.
Hence, there is a need to make sure the principal point overlaps with the image origin, and we add an offset \(o_x\) and \(o_y\) within the image plane to resolve this issue. Keep in mind that this offset is not caused by the movement of the object or the camera. It an intrinsic parameter of every camera.
The (2) becomes:
The focal length \(f\) need not be same along the \(x\) and \(y\) axes always. A general form of the projection matrix is:
This is the (Intrinsic) calibration matrix.
There is an advanced version of the above matrix. It is called Camera Calibration matrix.
\(\gamma\) - when you zoom in and zoom out, the \(x\) and \(y\) co-ordinates are changed proportionally. However if there is an unproportional change in \(x\) and \(y\) axes, \(\gamma\) takes care of that. \(\gamma\) is also called the aspect ratio of the pixel.
\(s\) - skew of the sensor pixel, i.e., if the pixel is a parallelogram and not a square.
There are 5 intrinsic parameters for a camera. Refer (5)
Extrinsic parameters of a camera#
The extrinsic parameters come into picture, even before shooting an image. Where the camera is located and it’s angle. (Rotation and Translation).
These are the parameters that identify uniquely the transformation between the unknown camera reference frame and the known world reference frame.
Determining these parameters includes:
Finding the translation vector between the relative positions of the origins of the two reference frames.
Finding the rotation matrix that brings the corresponding axes of the two frames into alignment (i.e., onto each other).
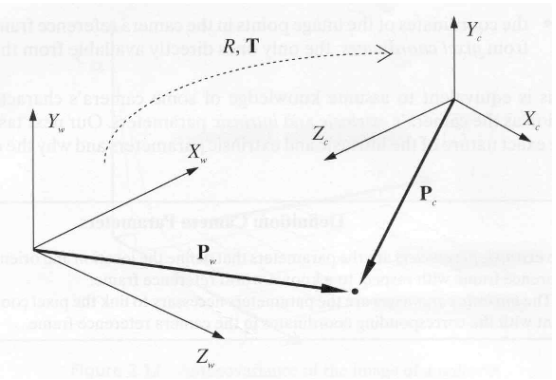
Fig. 4 Rotation and Translation from world coordinates to camera coordinates.#
Using the extrinsic camera parameters, we can find the relation between the coordinates of a point \(P\) in the world \((P_w)\) and camera \((P_c)\) coordinates:
where
In other words, we first translate the coordinates to match the camera coordinates and then rotate the axes so that both camera axes and world coordinate axes overlap.
where \(R_i^T\) corresponds to the \(i^{th}\) row of the rotation matrix.
What is a camera?
Camera is nothing but a 3D point to 2D point mapping function that has 11 parameters (intrinsic and extrinsic).
3D to 2D mapping (both intrinsic and extrinsic)#
Given an image of an object, we would like to find the intrinsic and extrinsic parameters of a camera.
With these intrinsic and extrinsic parameters, we want to use the camera to map any 3D point in the real world to a 2D coordinate on the image plane.
\([X_w, Y_w, Z_w]^T \rightarrow [X_c, Y_c, Z_c]^T\) is rigid transformation and \([X_c, Y_c, Z_c]^T \rightarrow s[x,y,1]\) is projective transformation (perspective projection).
\([x, y]^T\) are the image coordinates and \([X_w, Y_w, Z_w]^T\) are the world coordinates. \(T_{3 \times 1} = [T_x, T_y, T_z]^T\) is the translation vector.
The intrinsic and extrinsic parameters combine to form the matrix \(M\).
Intuition behind the 3D \(\rightarrow\) 2D mapping in a camera.#
Let’s suppose, you have \(n\) image coordinates of a camera and their corresponding world coordinates. Our aim to find the matrix \(M\). From (10), we have:
To solve for the matrix \(M\),
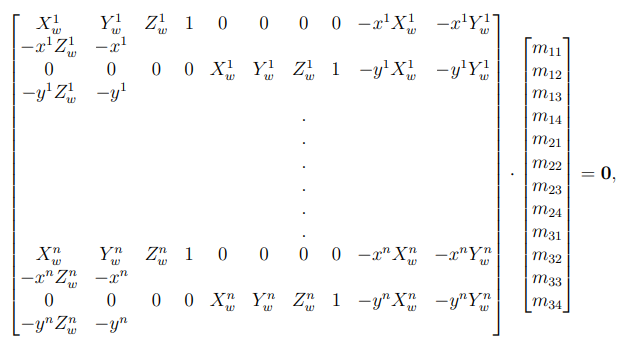
Fig. 5 Solving for the matrix \(M\)#
where the first matrix is of size \(2n \times 12\) (\(n\) is the number of available points.)
In the above homogeneous linear equation \(Ax=0\), we know the values of image coordinates and the real-world coordinates. We are required for find the elements of the matrix \(M\). The above equation has infinite solutions for \(Ax = 0\), since we can randomly scale \(x\) with a scalar \(\lambda\) such that \(A(\lambda x)= 0\). Therefore, we assume \(||x||=1\), solving the equation can be converted to:
The minimization problem can be solved with Singular Value Decomposition (SVD). Assume that \(A\) can be decomposed to \(U\Sigma V^T\), we have
Since \(||V^Tx||=||x||=1\), then we have \(min||Ax|| = ||\Sigma y||\).
As \(||y||=1\), \(x\) should be the last row of \(V^T\).
Once we have the matrix \(M\),
Here, \(M\) is the projection matrix. Let’s define
Also we define,
Observe that \((r_1, r_2, r_3)\) is the rotation matrix, then
Then we have \(r_i^Tr_i = 1, r_i^Tr_j=0 \enspace (i \neq j)\).
From \(M\) we have,
Summary#
This chapter discusses about the pinhole camera model. The intrinsic and extrinsic camera paramters. Given a 3D world coordinates of an object, a camera performs a 3D \(\rightarrow\) 2D mapping of the point onto an image plane. There are a total of 11 paramters for any camera to perform this perspective projection mapping.
This chapter also explains the mathematics used to find the intrinsic and extrinsic parameters of a camera using image coordinates and world coordinates. Given an image of an object, and \(n\) world coordinates and image coordinates, we discuss the mathematics to find the matrix \(M = M_{in}\cdot M_{ex}\) that would help us map any 3D point in real world to a 2D point on image plane.
The next chapter provides the code for the above mathematics. We use chessboard corners as objects and try to find the intrinsic and extrinsic parameters of a given camera.